rust网络框架Pingora源码阅读3
这应该是Pingora源码阅读的最后一篇文章,之前介绍了Pingora中两个比较重要的概念, Server和Service, 本篇文章着重于监听服务的钩子函数, 这也是我们主要写业务代码的地方。
Pingora代码版本: v0.1.0
internals.md在https://github.com/cloudflare/pingora/blob/main/docs/user_guide/internals.md
前情回顾
前面看到了HttpProxy的process_new_http方法(也就是HttpServerApp的实现), 到这一步及之前的代码都是协议的处理部分,比如会话的处理, 协议版本的协商等,这些HTTP1和HTTP2会有一些不同,但是后续的处理基本上是一致,也就是处理请求头,请求体等,以及将这些请求发送给后端,所以终于到了我们业务代码的地方,也就是ProxyHttp这个trait定义的各个钩子函数。
在此之前, 我们可以先看看官方给的请求处理的流程图。
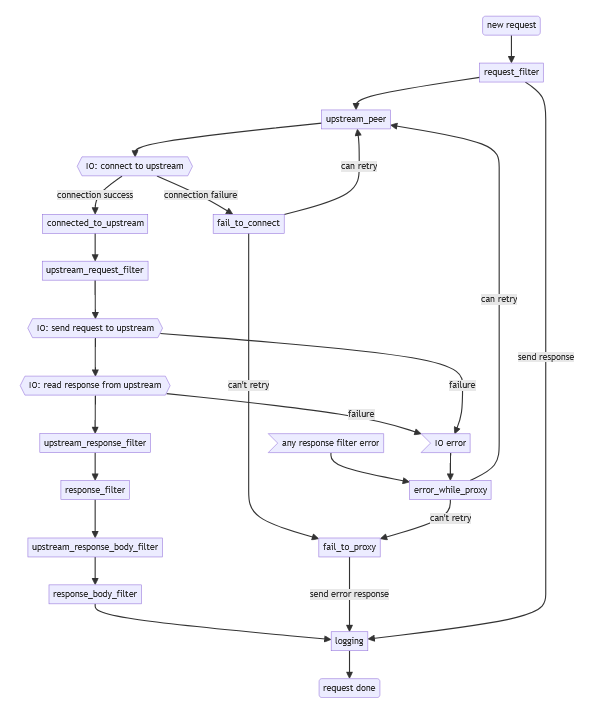
值得注意的是, 官方的示意图是省略了缓存部分的。
Pingora提供的钩子函数几乎都是_filter结尾, 即在某个特定的阶段处理该阶段的业务,而其他钩子函数fail_to_connect, fail_to_proxy和logging等从函数的名字就可以大致理解它的用处了,本文主要顺着示意图的最左边的数据流阅读Pingora的源代码。
上面的示意图的new_request就是前一篇文章的process_new_http的代码处,它会读取客户端的请求然后生成一个Session对象,这个Session对象会屏蔽不同协议之间的差异,在后续的请求处理过程中只需跟Session打交道就行,比如获取请求地址,请求头,请求体等。
async fn process_new_http(
self: &Arc<Self>,
session: HttpSession,
shutdown: &ShutdownWatch,
) -> Option<Stream> {
let session = Box::new(session);
// 开始读取请求并生成对应的Session对象
let mut session = match self.handle_new_request(session).await {
Some(downstream_session) => Session::new(downstream_session),
None => return None, // bad request
};
// 创建在各钩子函数之间共享的上下文CTX
let ctx = self.inner.new_ctx();
self.process_request(session, ctx).await
}
小结
在深入这个``process_request函数之前,我觉得Pingora`的钩子函数按阶段可以分成以下两类。
-
代理前 这部分可以控制是否请求以及请求哪个后端, 以及缓存
比如用于做验证,流控和访问控制的
request_filter函数, 以及用于获取要连接后端的upstream_peer -
代理后 这部分就是在发送前(发给后端前,发给客户端前)处理请求的各个部分
- 发送流量到
upstream之前 如connected_to_upstream,upstream_request_filter等 - 将
upstream的流量发送给downstream之前, 如upstream_response_filter,response_filter等
- 发送流量到
而按照功能来说可以分为以下三类
- 缓存类 要想提升性能,缓存绝对是一大利器,
pingora提供了各种缓存函数, 如request_cache_filter,response_cache_filter等函数 - 过滤类 这个就是处理请求各个阶段的各种
filter函数 - 错误处理类 提供出错时的回调以及重试机制回到
- 判断类 判断是否处理和发给哪个后端, 也就是
request_filter和upstream_peer函数。
process_request
由于代码太长,代码内部有说明,代码后也有重复的说明。
impl<SV> HttpProxy<SV> {
async fn process_request(
self: &Arc<Self>,
mut session: Session,
mut ctx: <SV as ProxyHttp>::CTX,
) -> Option<Stream>
where
SV: ProxyHttp + Send + Sync + 'static,
<SV as ProxyHttp>::CTX: Send + Sync,
{
// 1. 首先判断是否需要继续处理,如果返回`Ok(true)`就说明不用发给后端,直接返回就行
match self.inner.request_filter(&mut session, &mut ctx).await {
Ok(response_sent) => {
if response_sent {
// TODO: log error
self.inner.logging(&mut session, None, &mut ctx).await;
return session.downstream_session.finish().await.ok().flatten();
}
}
Err(e) => {
// 如果出错调用相关函数, 这里省略
}
}
// 2. 尝试获取客户端的压缩算法,如果没有启用就跳过
session
.downstream_compression
.request_filter(session.downstream_session.req_header());
// 3. 尝试跳过缓存返回,默认是禁用的,缓存的逻辑我没怎么看,所以不会深入
if let Some((reuse, err)) = self.proxy_cache(&mut session, &mut ctx).await {
// cache hit
return self.finish(session, &mut ctx, reuse, err.as_deref()).await;
}
//4. 再次判断是否应该将请求发送给后端,
match self
.inner
// 5. 可以用于cache没有命中就拒绝的流控情况。
.proxy_upstream_filter(&mut session, &mut ctx)
.await
{
Ok(proxy_to_upstream) => {
if !proxy_to_upstream {
// 只处理不往后端发的情况
}
}
Err(e) => {
// 调用钩子函数出错的情况省略...
}
}
let mut retries: usize = 0;
// 6. 这个可重用的变量很重要
let mut server_reuse = false;
let mut proxy_error: Option<Box<Error>> = None;
// 7. 最多允许重试16次
while retries < MAX_RETRIES {
retries += 1;
// 8. 开始转发请求了
let (reuse, e) = self.proxy_to_upstream(&mut session, &mut ctx).await;
server_reuse = reuse;
// 9. 如果出错了,但是可以重试那就尝试重试,否则就跳出循环
match e {
Some(error) => {
let retry = error.retry();
proxy_error = Some(error);
if !retry {
break;
}
}
None => {
proxy_error = None;
break;
}
};
}
// 10. 如果代理请求出错并可以尝试发送之前的缓存(如果启用缓存的话),那么就尝试发送缓存给客户端
let serve_stale_result = if proxy_error.is_some() && session.cache.can_serve_stale_error() {
self.handle_stale_if_error(&mut session, &mut ctx, proxy_error.as_ref().unwrap())
.await
} else {
None
};
// 11. 如果执行上一步,那么再次检查是否应该重用连接
let final_error = if let Some((reuse, stale_cache_error)) = serve_stale_result {
// don't reuse server conn if serve stale polluted it
server_reuse = server_reuse && reuse;
stale_cache_error
} else {
proxy_error
};
// 12. 如果发送缓存失败的话,就做一下收尾操作
if let Some(e) = final_error.as_ref() {
// 调用相关的钩子函数
}
// 13. 调用logging钩子函数以及返回是否重用的连接
self.finish(session, &mut ctx, server_reuse, final_error.as_deref())
.await
}
}
代码分解如下:
- 首先判断是否需要继续处理,如果返回
Ok(true)就说明不用发给后端,直接返回就行 - 尝试获取客户端的压缩算法,如果没有启用就跳过
- 尝试跳过缓存返回,默认是禁用的,缓存的逻辑我没怎么看,所以不会深入
- 再次判断是否应该将请求发送给后端
proxy_upstream_filter可以用于cache没有命中就拒绝的流控业务处理- 这个可重用的变量很重要,这些变量都很重要
- 最多允许重试16次
- 开始转发请求了
- 如果出错了,但是可以重试那就尝试重试,否则就跳出循环
- 如果代理请求出错并可以尝试发送之前的缓存(如果启用缓存的话),那么就尝试发送缓存给客户端
- 如果执行上一步,那么再次检查是否应该重用连接
- 如果发送缓存失败的话,就做一下收尾操作
- 调用
logging钩子函数以及返回是否重用连接
proxy_to_upstream
process_request主要的业务逻辑在于发送请求前和接受上游响应后,以及一些缓存的处理,而怎么将客户端的请求转发给后端,后端的请求怎么转发给客户端呢,这就交给proxy_to_upstream了。
async fn proxy_to_upstream(
&self,
session: &mut Session,
ctx: &mut SV::CTX,
) -> (bool, Option<Box<Error>>)
where
SV: ProxyHttp + Send + Sync,
SV::CTX: Send + Sync,
{
// 1.
let peer = match self.inner.upstream_peer(session, ctx).await {
Ok(p) => p,
Err(e) => return (false, Some(e)),
};
// 2.
let client_session = self.client_upstream.get_http_session(&*peer).await;
//
match client_session {
Ok((client_session, client_reused)) => {
let (server_reused, error) = match client_session {
ClientSession::H1(mut h1) => {
let (server_reused, client_reuse, error) = self
// 3.
.proxy_to_h1_upstream(session, &mut h1, client_reused, &peer, ctx)
.await;
// 4.
if client_reuse {
let session = ClientSession::H1(h1);
self.client_upstream
.release_http_session(session, &*peer, peer.idle_timeout())
.await;
}
(server_reused, error)
}
// 省略H2协议的处理细节
}
};
(
server_reused,
error.map(|e| {
self.inner
.error_while_proxy(&peer, session, e, ctx, client_reused)
}),
)
}
// 5.
Err(e) => {
let new_err = self.inner.fail_to_connect(session, &peer, ctx, e);
(false, Some(new_err.into_up()))
}
}
}
代码分解如下:
- 首先获取可以的后端对象
peer - 尝试从连接池中获取一个跟后端交互的连接
- 开始转发流量
- 如果可重用,用完自然要将会话放回资源池啦
- 错误处理
这部分代码会根据不同的协议调用不同的处理函数,本文只看http1协议的代码。
proxy_to_h1_upstream
下面的代码仅是调用一下钩子函数然后继续调用底层函数
pub(crate) async fn proxy_to_h1_upstream() -> (bool, bool, Option<Box<Error>>)
where
SV: ProxyHttp + Send + Sync,
SV::CTX: Send + Sync,
{
// 尝试调用connected_to_upstream钩子函数
if let Err(e) = self
.inner
.connected_to_upstream(
session,
reused,
peer,
client_session.id(),
Some(client_session.digest()),
ctx,
)
.await
{
return (false, false, Some(e));
}
// http1 到 http1 的流量转发
let (server_session_reuse, client_session_reuse, error) =
self.proxy_1to1(session, client_session, peer, ctx).await;
(server_session_reuse, client_session_reuse, error)
}
proxy_1to1
流量的转发主要就在这了。
impl<SV> HttpProxy<SV> {
pub(crate) async fn proxy_1to1() -> (bool, bool, Option<Box<Error>>)
where
SV: ProxyHttp + Send + Sync,
SV::CTX: Send + Sync,
{
// 1.
client_session.read_timeout = peer.options.read_timeout;
client_session.write_timeout = peer.options.write_timeout;
let mut req = session.req_header().clone();
//
if req.version == Version::HTTP_2 {
// 什么情况下会需要转换协议?这里不太懂
}
// 2.
match self
.inner
.upstream_request_filter(session, &mut req, ctx)
.await
{
Ok(_) => { /* continue */ }
Err(e) => {
return (false, true, Some(e));
}
}
// 3.
session.upstream_compression.request_filter(&req);
// 4.
//
let (tx_upstream, rx_upstream) = mpsc::channel::<HttpTask>(TASK_BUFFER_SIZE);
let (tx_downstream, rx_downstream) = mpsc::channel::<HttpTask>(TASK_BUFFER_SIZE);
session.as_mut().enable_retry_buffering();
// 5.
let ret = tokio::try_join!(
self.proxy_handle_downstream(session, tx_downstream, rx_upstream, ctx),
self.proxy_handle_upstream(client_session, tx_upstream, rx_downstream),
);
match ret {
Ok((_first, _second)) => {
client_session.respect_keepalive();
(true, true, None)
}
Err(e) => (false, false, Some(e)),
}
}
}
代码分解如下:
-
设置各种超时
-
尝试将请求发送给后端之前调用钩子函数
-
用于解析各种压缩算法
-
将跟客户端和后端建立的连接分别分割成发送端和接收端
这样就可以像linux的管道一样,将客户端的发送端与后端的接收端相连,反过来也一样
-
开启双相传输流,同时启动两个异步任务并等待
后面的请求转发就不继续看了,无非是调用钩子函数以及复制字节流了。
总结
本系列文档大致的介绍了Pingora的两个核心对象Server和Service, 前者代表整个程序,后者代表我们的业务服务,最常见也最重要的服务就是代理服务了,我们只需要实现ProxyHttp trait的upstream_peer就能完成HTTP1或者HTTP2协议的流量转发了。
Pingora提供了比较多的钩子函数用于处理代理转发的各个阶段,基于业务需求,我们可以方便的实现流控以及负载均衡等业务。