kube-proxy保姆级别源码阅读
kube-proxy在kubernetes中扮演的角色是主机间网络流量的协同者, kube-proxy通过实时监听网络变化来管理转发和路由, 但是根据所选的cni不通以及网络类型的选择(iptables, ipvs)不同会有不同的效果
特别说明: kubernetes源代码版本: 1.22 commit: fba7198a2cc81c4602f358c7b77ee4e733d20aa2
阅读一个项目的源代码带着问题去阅读是一个不错的选择,下面是我之前存在的问题,答案在最后。
-
为什么理论上ipvs的转发性能高于iptables却默认是iptables而不是ipvs?
-
kube-proxy怎么保持规则的同步和生成对应的规则,第一次全量数据是怎么拿到的?
-
iptables怎么保留iptables上已有的规则,怎么确保自己的规则没有被刷掉?
kube-proxy在linux上一共有三种模式, userspace, iptables, ipvs, 现在默认是iptables
其中userspace基本不会再用,因为性能较之后两者太差。
本文主要阅读是iptables代理模式下的kube-proxy代码,所以ipvs相关代码不会在本文体现。
kube-proxy代码大概分为三个部分。
-
初始化,即命令行解析,环境检查,内核参数配置等。
-
启动流程,即ProxyServer的运行逻辑
-
事件监听/规则同步, 监听endpointslice(或endpoint), service, node等资源变化,并根据变化来生成并写入规则到iptables。
但是有一部分比较有趣也相对比较难的是在iptables规则创建之后的pod与pod之间的数据流向,这一部分作为本文的最后一部分,如果大家觉得代码看起来比较枯燥,可以直接看第四部分来了解数据流向,方便排查问题。
注意: 结合文中代码里面的注释食用效果更佳,因为有些说明跟代码放在一起更适合, 然后就是会削减一定的代码来保证文章不会过于冗长。
初始化
k8s所有的组件都是使用的cobra这个命令行解析库来解析命令行,模式都差不多,代码如下:
// cmd\kube-proxy\proxy.go
func main() {
// 创建command对象并执行
command := app.NewProxyCommand()
if err := command.Execute(); err != nil {
os.Exit(1)
}
}
// cmd\kube-proxy\app\server.go
func NewProxyCommand() *cobra.Command {
// k8s每个组件都有类似的*options对象用来存储用户的配置
opts := NewOptions()
cmd := &cobra.Command{
Run: func(cmd *cobra.Command, args []string) {
// 如果是windows则配置系统
if err := initForOS(opts.WindowsService); err != nil {
klog.Fatalf("failed OS init: %v", err)
}
// 填充默认参数
if err := opts.Complete(); err != nil {
klog.Fatalf("failed complete: %v", err)
}
// 验证参数是否合法
if err := opts.Validate(); err != nil {
klog.Fatalf("failed validate: %v", err)
}
// 基于所给的参数运行
if err := opts.Run(); err != nil {
klog.Exit(err)
}
},
}
// 应用默认值和添加命令行参数
var err error
opts.config, err = opts.ApplyDefaults(opts.config)
opts.AddFlags(cmd.Flags())
cmd.MarkFlagFilename("config", "yaml", "yml", "json")
return cmd
}
func (o *Options) Complete() error {
// Load the config file here in Complete, so that Validate validates the fully-resolved config.
if len(o.ConfigFile) > 0 {
// 读取本地配置文件
c, err := o.loadConfigFromFile(o.ConfigFile)
o.config = c
// 用来监听配置文件是否发生变化, 如果修改,重命名等情况就会触发一个error
// 会导致kube-proxy退出,因为在pod里面,所以会导致重启
if err := o.initWatcher(); err != nil {
return err
}
}
//
return utilfeature.DefaultMutableFeatureGate.SetFromMap(o.config.FeatureGates)
}
k8s各组件的启动流程一般是将用户参数和指定的配置文件解析到一个*Options对象中,然后填充默认参数,验证参数,最后基于这些参数构造组件实例并运行,kube-proxy也是如此。
在Options里面有四个比较重要的对象。
type Options struct {
// kube-proxy配置文件位置, 如/var/lib/kube-proxy/config.conf
ConfigFile string
// 用来运行kube-proxy所需的配置参数
config *kubeproxyconfig.KubeProxyConfiguration
// 一个proxyServer对象
proxyServer proxyRun
// kube-apiserver的地址
master string
}
其中proxyServer是一个在proxier之上更高级的抽象,proxier属于负责底层干活的对象,用于直接与iptables或ipvs等代理模式的具体实现交互,而ProxyServer用来做一些通用的操作,以及决定用那种模式的代理
然后我们来看看Options对象是如何将kube-proxy拉起来的,从上文我们知道运行时调用的opts.Run(),代码如下:
// 创建ProxyServer对象并运行循环
func (o *Options) Run() error {
proxyServer, err := NewProxyServer(o)
o.proxyServer = proxyServer
return o.runLoop()
}
//
func (o *Options) runLoop() error {
// 启动文件监听器,监听配置文件的是否发生非预期的变化
if o.watcher != nil {
o.watcher.Run()
}
// proxyServer对象以一个额外的gorouting启动
go func() {
err := o.proxyServer.Run()
o.errCh <- err
}()
// 进入死循环,直至发生错误, 才会退出
for {
err := <-o.errCh
if err != nil {
return err
}
}
}
可以看到主进程在启动之后拉起proxyServer之后就会进入死循环,直至发生错误才会退出,也可以看到后续的逻辑交给了ProxyServer来执行,即o.proxyServer.Run()。
那么在回过头看看ProxyServer怎么创建以及怎么运行。
注意: NewProxyServer有windows版本和其他系统两个版本,这里自然是要看linux版本的,所以代码在cmd\kube-proxy\app\server_others.go
// cmd\kube-proxy\app\server_others.go
func NewProxyServer(o *Options) (*ProxyServer, error) {
return newProxyServer(o.config, o.CleanupAndExit, o.master)
}
func newProxyServer(
config *proxyconfigapi.KubeProxyConfiguration,
cleanupAndExit bool,
master string) (*ProxyServer, error) {
// /configz 用来检查运行时的配置
if c, err := configz.New(proxyconfigapi.GroupName); err == nil {
c.Set(config)
}
// 用来操作iptables和内核的接口
var iptInterface utiliptables.Interface
var kernelHandler ipvs.KernelHandler
// 用来操作iptables的命令行接口
// 即os/exec的封装,用来执行iptables等命令
execer := exec.New()
kernelHandler = ipvs.NewLinuxKernelHandler()
// 创建可以跟k8s集群交互的client
client, eventClient, err := createClients(config.ClientConnection, master)
// 拿到运行节点的ip
nodeIP := detectNodeIP(client, hostname, config.BindAddress)
// 用来传播事件的对象, 即kubectl get events
eventBroadcaster := events.NewBroadcaster(&events.EventSinkImpl{Interface: client.EventsV1()})
recorder := eventBroadcaster.NewRecorder(scheme.Scheme, "kube-proxy")
// 一个用来表示当前节点的引用对象
nodeRef := &v1.ObjectReference{
Kind: "Node",
Name: hostname,
UID: types.UID(hostname),
Namespace: "",
}
// proxier 代理模式的具体实现
var proxier proxy.Provider
var detectLocalMode proxyconfigapi.LocalMode
// 得到代理模式
proxyMode := getProxyMode(string(config.Mode), canUseIPVS, iptables.LinuxKernelCompatTester{})
// 判断是否检查本地流量,即同一节点的两个pod交互的流量
detectLocalMode, err = getDetectLocalMode(config)
// iptables有ipv4和ipv6协议, 默认是只有ipv4
primaryProtocol := utiliptables.ProtocolIPv4
iptInterface = utiliptables.New(execer, primaryProtocol)
var ipt [2]utiliptables.Interface
// 判断是否同时启用ipv4和ipv6, 默认只有ipv4
dualStack := utilfeature.DefaultFeatureGate.Enabled(features.IPv6DualStack) && proxyMode != proxyModeUserspace
if proxyMode == proxyModeIPTables {
if dualStack {
// 移除了创建双栈(ipv4+ipv6)的逻辑
} else { // Create a single-stack proxier.
// 探测本地流量应该为了TopologyAwareHints特性
var localDetector proxyutiliptables.LocalTrafficDetector
localDetector, err = getLocalDetector(detectLocalMode, config, iptInterface, nodeInfo)
// TODO this has side effects that should only happen when Run() is invoked.
proxier, err = iptables.NewProxier(
// 操作iptables命令的接口, 创建/删除/确认等操作。
iptInterface,
// 用来操作/proc/sys内核参数,如内存分配策略vm/overcommit_memory
utilsysctl.New(),
execer,
config.IPTables.SyncPeriod.Duration,
config.IPTables.MinSyncPeriod.Duration,
config.IPTables.MasqueradeAll,
int(*config.IPTables.MasqueradeBit),
localDetector,
hostname,
nodeIP,
recorder,
healthzServer,
config.NodePortAddresses,
)
}
proxymetrics.RegisterMetrics()
}
// 删除了ipvs相关代码
useEndpointSlices := true
return &ProxyServer{
Client: client,
EventClient: eventClient,
IptInterface: iptInterface,
IpvsInterface: ipvsInterface,
IpsetInterface: ipsetInterface,
execer: execer,
Proxier: proxier,
Broadcaster: eventBroadcaster,
Recorder: recorder,
ConntrackConfiguration: config.Conntrack,
// 用来操作/proc/sys/net/netfilter等参数
// snat/dnat都需要内核跟踪建立的连接
Conntracker: &realConntracker{},
ProxyMode: proxyMode,
NodeRef: nodeRef,
MetricsBindAddress: config.MetricsBindAddress,
BindAddressHardFail: config.BindAddressHardFail,
EnableProfiling: config.EnableProfiling,
OOMScoreAdj: config.OOMScoreAdj,
ConfigSyncPeriod: config.ConfigSyncPeriod.Duration,
HealthzServer: healthzServer,
UseEndpointSlices: useEndpointSlices,
}, nil
}
这样一个ProxyServer 就初始化完成了,整个过程就是根据代理模式创建对应的接口和对象。
小结
通过这部的代码可以发现,初始化主要分为两个部分,一个是参数解析和填充,一个是ProxyServer的创建逻辑。之所以在proxier之上在抽象出来一个proxyServer是为了让proxier的功能更加纯粹,proxier只需负责同步规则即可,而proxyServer会适配各个proxier,并在这些proxier中选择一个合适的,以及将各个proxier之间一些通用的操作抽象出来放在proxyServer的逻辑中统一处理。
启动流程
在环境初始化完成之后就是启动流程了,主进程在启动之后拉起proxyServer之后就会进入死循环,直至发生错误才会退出,而kube-proxy的主要业务逻辑交给了proxyServer。
主进程回顾:
func (o *Options) Run() error {
proxyServer, err := NewProxyServer(o)
o.proxyServer = proxyServer
return o.runLoop()
}
func (o *Options) runLoop() error {
go func() {
err := o.proxyServer.Run()
o.errCh <- err
}()
for {
err := <-o.errCh
if err != nil {
return err
}
}
}
可以看到proxyServer通过o.proxyServer.Run()启动。
// cmd\kube-proxy\app\server.go
func (s *ProxyServer) Run() error {
// 用来跳转OOM参数,保证系统在内存紧张的时候不优先kill掉kube-proxy的进程
var oomAdjuster *oom.OOMAdjuster
if s.OOMScoreAdj != nil {
oomAdjuster = oom.NewOOMAdjuster()
if err := oomAdjuster.ApplyOOMScoreAdj(0, int(*s.OOMScoreAdj)); err != nil {
klog.V(2).Info(err)
}
}
// 根据kube-proxy命令行参数或配置文件跳转conntrack参数
// 主要是tcp建立连接的相关参数,比如超时,存活检查(keepalive)等, 以及最大连接数等
if s.Conntracker != nil {
max, err := getConntrackMax(s.ConntrackConfiguration)
if err != nil {
return err
}
if max > 0 {
err := s.Conntracker.SetMax(max
}
// TCP相关参数
if s.ConntrackConfiguration.TCPEstablishedTimeout != nil && s.ConntrackConfiguration.TCPEstablishedTimeout.Duration > 0 {
timeout := int(s.ConntrackConfiguration.TCPEstablishedTimeout.Duration / time.Second)
if err := s.Conntracker.SetTCPEstablishedTimeout(timeout); err != nil {
return err
}
}
if s.ConntrackConfiguration.TCPCloseWaitTimeout != nil && s.ConntrackConfiguration.TCPCloseWaitTimeout.Duration > 0 {
timeout := int(s.ConntrackConfiguration.TCPCloseWaitTimeout.Duration / time.Second)
if err := s.Conntracker.SetTCPCloseWaitTimeout(timeout); err != nil {
return err
}
}
}
// 这里创建informer工厂函数,最后创建相应的informer用于监听service,endpointslice等资源
// 这两个NewRequirement用来过滤掉serviceProxyName和noheadless的endpoint
noProxyName, err := labels.NewRequirement(apis.LabelServiceProxyName, selection.DoesNotExist, nil)
if err != nil {
return err
}
noHeadlessEndpoints, err := labels.NewRequirement(v1.IsHeadlessService, selection.DoesNotExist, nil)
if err != nil {
return err
}
labelSelector := labels.NewSelector()
labelSelector = labelSelector.Add(*noProxyName, *noHeadlessEndpoints)
informerFactory := informers.NewSharedInformerFactoryWithOptions(s.Client, s.ConfigSyncPeriod,
informers.WithTweakListOptions(func(options *metav1.ListOptions) {
options.LabelSelector = labelSelector.String()
}))
// 开始创建相应的informer并注册事件函数
// 依次是service informer, endpointslieces informer
serviceConfig := config.NewServiceConfig(informerFactory.Core().V1().Services(), s.ConfigSyncPeriod)
serviceConfig.RegisterEventHandler(s.Proxier)
go serviceConfig.Run(wait.NeverStop)
if s.UseEndpointSlices {
endpointSliceConfig := config.NewEndpointSliceConfig(informerFactory.Discovery().V1().EndpointSlices(), s.ConfigSyncPeriod)
endpointSliceConfig.RegisterEventHandler(s.Proxier)
go endpointSliceConfig.Run(wait.NeverStop)
} else {
endpointsConfig := config.NewEndpointsConfig(informerFactory.Core().V1().Endpoints(), s.ConfigSyncPeriod)
endpointsConfig.RegisterEventHandler(s.Proxier)
go endpointsConfig.Run(wait.NeverStop)
}
// 启动所有informer
informerFactory.Start(wait.NeverStop)
// 判断是否启用TopologyAwareHints特性以创建node informer
// 首次触发一次同步。
s.birthCry()
// 最后启动同步规则的循环
go s.Proxier.SyncLoop()
// 如果错误出现就退出
return <-errCh
}
pkg\features\kube_features.go里面有当前版本的各个特性的默认值
ProxyServer的运行逻辑概括起来就是根据配置参数(命令行参数,配置文件)来配置系统内核参数,比如OOM分值,nf_conntrack等参数。
然后创建service informer, endpointslices informer,并将proxier对象作为事件回调函数传给informer用来响应informer的事件,proxier实现了OnServiceAdd,OnServiceUpdate等接口。
最后启动informer并触发首次更新以及运行同步规则的循环。
其中birthCry比较简单,就是输出一个事件, 告诉集群启动了。
func (s *ProxyServer) birthCry() {
s.Recorder.Eventf(s.NodeRef, nil, api.EventTypeNormal, "Starting", "StartKubeProxy", "")
}
在启动步骤中比较核心的是service,endpoint等informer的创建和事件函数的注册,以service informer为例,代码如下:
// pkg\proxy\config\config.go
func NewServiceConfig(serviceInformer coreinformers.ServiceInformer, resyncPeriod time.Duration) *ServiceConfig {
result := &ServiceConfig{
listerSynced: serviceInformer.Informer().HasSynced,
}
// 创建informer并注册事件函数
serviceInformer.Informer().AddEventHandlerWithResyncPeriod(
cache.ResourceEventHandlerFuncs{
AddFunc: result.handleAddService,
UpdateFunc: result.handleUpdateService,
DeleteFunc: result.handleDeleteService,
},
resyncPeriod,
)
return result
}
// 将事件回调函数加入eventhandlers中,在每次触发事件的时候调用
func (c *ServiceConfig) RegisterEventHandler(handler ServiceHandler) {
c.eventHandlers = append(c.eventHandlers, handler)
}
// 等待数据同步完成后,调用OnServiceSynced事件回调函数
func (c *ServiceConfig) Run(stopCh <-chan struct{}) {
klog.Info("Starting service config controller")
// 等待数据同步
if !cache.WaitForNamedCacheSync("service config", stopCh, c.listerSynced) {
return
}
// 调用proxier的OnServiceSynced方法
for i := range c.eventHandlers {
klog.V(3).Info("Calling handler.OnServiceSynced()")
c.eventHandlers[i].OnServiceSynced()
}
}
关于这些informer的事件函数暂时按下不表,因为事件监听的逻辑会在本文的第三部分着重说明。
在阅读syncLoop的代码之前,我们还需要看看proxier的创建流程。
// pkg\proxy\iptables\proxier.go
func NewProxier(ipt utiliptables.Interface,
sysctl utilsysctl.Interface,
exec utilexec.Interface,
syncPeriod time.Duration,
minSyncPeriod time.Duration,
masqueradeAll bool,
masqueradeBit int,
localDetector proxyutiliptables.LocalTrafficDetector,
hostname string,
nodeIP net.IP,
recorder events.EventRecorder,
healthzServer healthcheck.ProxierHealthUpdater,
nodePortAddresses []string,
) (*Proxier, error) {
// 正常情况下,内核不会对地址localnet(127.0.0.1/8)的地址做forwarding, 因为这部分代码被认为是martian.
// 但是可以通过内核中配置来启用route_localnet
if err := utilproxy.EnsureSysctl(sysctl, sysctlRouteLocalnet, 1); err != nil {
return nil, err
}
// 确保bridge-nf-call-iptabels=1
if val, err := sysctl.GetSysctl(sysctlBridgeCallIPTables); err == nil && val != 1 {
klog.InfoS("Missing br-netfilter module or unset sysctl br-nf-call-iptables; proxy may not work as intended")
}
// 对snat数据流做标记
masqueradeValue := 1 << uint(masqueradeBit)
masqueradeMark := fmt.Sprintf("%#08x", masqueradeValue)
klog.V(2).InfoS("Using iptables mark for masquerade", "ipFamily", ipt.Protocol(), "mark", masqueradeMark)
serviceHealthServer := healthcheck.NewServiceHealthServer(hostname, recorder)
ipFamily := v1.IPv4Protocol
if ipt.IsIPv6() {
ipFamily = v1.IPv6Protocol
}
ipFamilyMap := utilproxy.MapCIDRsByIPFamily(nodePortAddresses)
nodePortAddresses = ipFamilyMap[ipFamily]
// Log the IPs not matching the ipFamily
if ips, ok := ipFamilyMap[utilproxy.OtherIPFamily(ipFamily)]; ok && len(ips) > 0 {
klog.InfoS("Found node IPs of the wrong family", "ipFamily", ipFamily, "ips", strings.Join(ips, ","))
}
proxier := &Proxier{
//各个参数..
}
// 瞬时并发数量
burstSyncs := 2
klog.V(2).InfoS("Iptables sync params", "ipFamily", ipt.Protocol(), "minSyncPeriod", minSyncPeriod, "syncPeriod", syncPeriod, "burstSyncs", burstSyncs)
// 创建一个syncRunner 对象,它会保证每个任务之间的时间间隔不大于minSyncPeriod
// 并且最少maxInterval(这里默认是time.Hour, 一个小时)同步一次
// 说明kube-proxy至少每个小时会触发一次同步
// **但是同步不一定代表会刷新规则**
// syncRunner会控制并发。
proxier.syncRunner = async.NewBoundedFrequencyRunner("sync-runner", proxier.syncProxyRules, minSyncPeriod, time.Hour, burstSyncs)
// 通过创建一个KUBE-KUBELET-CANARY的链来检测iptables规则是否被刷掉(iptables flush)
// 如果这个链不存在了,自然说明规则链被清理掉了。
go ipt.Monitor(kubeProxyCanaryChain, []utiliptables.Table{utiliptables.TableMangle, utiliptables.TableNAT, utiliptables.TableFilter},
proxier.syncProxyRules, syncPeriod, wait.NeverStop)
return proxier, nil
}
如果你遇到了两个pod在不同的机器上可以通信正常而同一机器上却失败,那么你可以看看参数bridge-nf-call-iptabels是否为1
假设pod1,pod2在同一台机器上,并且svc2指向pod2
如果本地的pod1访问svc2, 那么数据流是pod1 -> svc2 cluster ip -> dnat -> pod2 pod2在接收到数据包后发现,数据来自同一局域网,那么会直接在二层(网桥)回包,但是pod1并不是走二层(网桥)来的包,所以会导致数据流不匹配,那么无法建立连接,所以这个参数保证pod2在回包的时候,还是会走iptables, 即网桥的数据流会过iptables,这样iptables回将数据包原路返回。
通过阅读proxier创建的代码,我们知道一些比较重要的参数,比如bridge-nf-call-iptabels,以及kube-proxy如何通过创建一个不适用的KUBE-KUBELET-CANARY链来检测规则是否被刷掉。
proxier里面有一个比较重要的对象syncRunner, 后续的所有规则都会通过这个对象作为同步规则的入口,这个对象会控制并发的竞争,也会控制每次同步的最大间隔和最小间隔。
在进入第三部分之前,我们在回顾一下ProxyServer的启动过程。
func (s *ProxyServer) Run() error {
// 创建informer等操作....
s.birthCry()
// 启动proxier的同步规则的循环
go s.Proxier.SyncLoop()
return <-errCh
}
// pkg\proxy\iptables\proxier.go
func (proxier *Proxier) SyncLoop() {
// 调用syncRunner
proxier.syncRunner.Loop(wait.NeverStop)
}
// pkg\util\async\bounded_frequency_runner.go
func (bfr *BoundedFrequencyRunner) Loop(stop <-chan struct{}) {
klog.V(3).Infof("%s Loop running", bfr.name)
// 重置定时器, 即bfr.timer.C(),下次的启动时间是当前时间加上maxInterval
bfr.timer.Reset(bfr.maxInterval)
for {
select {
case <-stop:
bfr.stop()
klog.V(3).Infof("%s Loop stopping", bfr.name)
return
case <-bfr.timer.C():
bfr.tryRun()
case <-bfr.run:
bfr.tryRun()
case <-bfr.retry:
bfr.doRetry()
}
}
}
func (bfr *BoundedFrequencyRunner) tryRun() {
bfr.mu.Lock()
defer bfr.mu.Unlock()
// 获取令牌控制并发。
if bfr.limiter.TryAccept() {
// 这里的fn就是proxier.syncProxyRules
bfr.fn()
bfr.lastRun = bfr.timer.Now()
bfr.timer.Stop()
bfr.timer.Reset(bfr.maxInterval)
klog.V(3).Infof("%s: ran, next possible in %v, periodic in %v", bfr.name, bfr.minInterval, bfr.maxInterval)
return
}
}
从上面的代码可以看到,最终还是调用syncRunner的Loop方法, 从这里开始,同步的规则的逻辑全部交给了proxier,这部分可能就是kube-proxy最重要的部分了。
小结
至此,我们了解到了ProxyServer会配置一些系统通用的内核参数,然后在创建proxier的时候,每个proxier的创建过程中会根据自己的需要配置一些必要的系统参数。iptables proxier在创建过程中还会启动一个monitor用来监测iptables规则是否被刷掉,以触发同步规则的任务,而创建过程中比较核心的一个对象是syncRunner,这个对象会控制规则同步任务之间的时间间隔,最少多久时间同步一次以及任务的并发。
上文中的任务,其实就是一次触发, 最终调用的方法都是一致的, 即proxier.syncProxyRules
事件监听/规则同步
在ProxyServer的启动流程我们知道proxier被作为handler注册到Service, endpointslice的informer事件函数中。
现在我们来看看iptables模式的各个事件回调函数的实现,本文假设kube-proxy是首次启动,并且以OnServiceAdd作为线索来跟踪代码。
informer在启动之后,在同步数据的时候会调用回调函数
OnXXXAdd函数。
func (proxier *Proxier) OnServiceAdd(service *v1.Service) {
proxier.OnServiceUpdate(nil, service)
}
func (proxier *Proxier) OnServiceUpdate(oldService, service *v1.Service) {
// proxier.isInitialized在informer首次同步完成之后才会返回true
if proxier.serviceChanges.Update(oldService, service) && proxier.isInitialized() {
proxier.Sync()
}
}
上面的代码逻辑很简单,如果看OnServiceDelete会发现也是调用OnServiceUpdate,而endpointSlice的逻辑也差不多。
总的来说,大体逻辑都是最终聚合到proxier.XXXXChanges.Update这个方法里面,统一添加,删除,更新。
proxier对象里面有两种比较重要的数据结构
-
XXXMap(serviceMap, endpointsMap): 这个结构用来保存当前代理规则的状态(service, endpoints)
-
XXXChanges(serviceChanges, endpointsChanges), 用来记录同步前发生的状态变化,每次同步之后就会清空。
从上面我们知道,service的变更最终调用的都是proxier.serviceChanges.Update, 以下是它的代码.
// pkg\proxy\service.go
// 增加对象
// 传递参数 nil, service
// 删除对象
// 传递参数 service, nil
// 更新对象
// 传递参数 oldService, currentService
func (sct *ServiceChangeTracker) Update(previous, current *v1.Service) bool {
svc := current
if svc == nil {
svc = previous
}
// 如果previous, current都是nil, 直接返回
if svc == nil {
return false
}
// 用来定位唯一的service, 在一个集群中namespace+servicename是唯一的
namespacedName := types.NamespacedName{Namespace: svc.Namespace, Name: svc.Name}
// 判断是否已经在变更中存在
change, exists := sct.items[namespacedName]
// 如果不存在,说明是一个新增操作
if !exists {
change = &serviceChange{}
// 根据service对象创建serviceMap对象
change.previous = sct.serviceToServiceMap(previous)
sct.items[namespacedName] = change
}
change.current = sct.serviceToServiceMap(current)
// 判断是否有变化,没变化就没必要加入到变更里面了
if reflect.DeepEqual(change.previous, change.current) {
delete(sct.items, namespacedName)
} else {
klog.V(2).Infof("Service %s updated: %d ports", namespacedName, len(change.current))
}
return len(sct.items) > 0
}
proxier.serviceChanges.Update的操作比较简单,就是将变更加入到自己的变更(change items)切片中, 否则什么都不做。
至此,每个service和endpoints对象都被添加到了XXXChanges对象里面了。
当informer数据同步完成之后,就会开始规则的同步了,而在数据同步完成之前,所有的数据也都加入到了XXXChanges里面了。
syncProxyRules
规则同步的这个函数超级长,所以这里会将这个函数的功能分为以下几个部分来讲解。
-
计算要更新的规则
-
iptables前置操作
-
根据最新的数据创建规则和规则链
-
删除不再使用的规则和规则链
-
刷新iptables规则
-
删除过时的conntrack连接
计算规则
这部分主要就是将serviceChanges, endpointsChanges更新到serviceMap和endpointsMap, 后续的操作都是以此为基础来做相应的操作的。
代码如下:
// pkg\proxy\iptables\proxier.go
// 根据changes与当前map来计算最终的代理规则
serviceUpdateResult := proxier.serviceMap.Update(proxier.serviceChanges)
endpointUpdateResult := proxier.endpointsMap.Update(proxier.endpointsChanges)
// pkg\proxy\service.go
func (sm ServiceMap) Update(changes *ServiceChangeTracker) (result UpdateServiceMapResult) {
result.UDPStaleClusterIP = sets.NewString()
// 应用changes
sm.apply(changes, result.UDPStaleClusterIP)
// 用来健康检查的端口
result.HCServiceNodePorts = make(map[types.NamespacedName]uint16)
for svcPortName, info := range sm {
if info.HealthCheckNodePort() != 0 {
result.HCServiceNodePorts[svcPortName.NamespacedName] = uint16(info.HealthCheckNodePort())
}
}
return result
}
// 将changes里的数据合并到serviceMap里面, 然后将changes置为空
func (sm *ServiceMap) apply(changes *ServiceChangeTracker, UDPStaleClusterIP sets.String) {
for _, change := range changes.items {
// 合并, 过滤, 删除
sm.merge(change.current)
change.previous.filter(change.current)
sm.unmerge(change.previous, UDPStaleClusterIP)
}
// 置为空
changes.items = make(map[types.NamespacedName]*serviceChange)
metrics.ServiceChangesPending.Set(0)
}
计算规则产生的结果是最新的状态,然后与旧的状态相比较就可以得到过时的规则,根据这些过时的规则可以用于后续清理操作。
如果过时的连接不清理,就会操作网络异常,比如后端已经改变,但是conntrack那里还保持连接,那么连接不清理掉的话,就会导致访问到旧的后端,或者访问到没有响应的对端。
下面是将这些过时的数据保存起来,以便后续清理。
// 初始化化空对象
conntrackCleanupServiceIPs := serviceUpdateResult.UDPStaleClusterIP
conntrackCleanupServiceNodePorts := sets.NewInt()
// 基于这些差异结果来插入过时的数据,用于后续清理
for _, svcPortName := range endpointUpdateResult.StaleServiceNames {
if svcInfo, ok := proxier.serviceMap[svcPortName]; ok && svcInfo != nil && conntrack.IsClearConntrackNeeded(svcInfo.Protocol()) {
conntrackCleanupServiceIPs.Insert(svcInfo.ClusterIP().String())
for _, extIP := range svcInfo.ExternalIPStrings() {
conntrackCleanupServiceIPs.Insert(extIP)
}
for _, lbIP := range svcInfo.LoadBalancerIPStrings() {
conntrackCleanupServiceIPs.Insert(lbIP)
}
nodePort := svcInfo.NodePort()
if svcInfo.Protocol() == v1.ProtocolUDP && nodePort != 0 {
klog.V(2).Infof("Stale %s service NodePort %v -> %d", strings.ToLower(string(svcInfo.Protocol())), svcPortName, nodePort)
conntrackCleanupServiceNodePorts.Insert(nodePort)
}
}
}
iptables前置操作
这一部分确保在写入规则到iptables之前一些规则链和规则必须存在,如果不存在就创建。
// iptablesJumpChains是一个切片,包含各个表的各个链
for _, jump := range iptablesJumpChains {
if _, err := proxier.iptables.EnsureChain(jump.table, jump.dstChain); err != nil {
klog.ErrorS(err, "Failed to ensure chain exists", "table", jump.table, "chain", jump.dstChain)
return
}
args := append(jump.extraArgs,
"-m", "comment", "--comment", jump.comment,
"-j", string(jump.dstChain),
)
if _, err := proxier.iptables.EnsureRule(utiliptables.Prepend, jump.table, jump.srcChain, args...); err != nil {
klog.ErrorS(err, "Failed to ensure chain jumps", "table", jump.table, "srcChain", jump.srcChain, "dstChain", jump.dstChain)
return
}
}
// 确保KUBE-MARK-DROP规则链存在
for _, ch := range iptablesEnsureChains {
if _, err := proxier.iptables.EnsureChain(ch.table, ch.chain); err != nil {
klog.ErrorS(err, "Failed to ensure chain exists", "table", ch.table, "chain", ch.chain)
return
}
}
EnsureXXX的逻辑都是首先检查是否存在,如果存在就返回,否则就尝试创建。
在所需要的规则和规则链确认存在之后就是将所有规则导出。
// 通过iptables-save -t nat/filter命令将相应的表的数据导出
// filter表数据导出
existingFilterChains := make(map[utiliptables.Chain][]byte)
proxier.existingFilterChainsData.Reset()
err := proxier.iptables.SaveInto(utiliptables.TableFilter, proxier.existingFilterChainsData)
if err != nil { // if we failed to get any rules
klog.ErrorS(err, "Failed to execute iptables-save, syncing all rules")
} else {
// 将导出数据中的规则链列表导出
existingFilterChains = utiliptables.GetChainLines(utiliptables.TableFilter, proxier.existingFilterChainsData.Bytes())
}
// nat表数据导出
// 与filter表差不多
existingNATChains := make(map[utiliptables.Chain][]byte)
proxier.iptablesData.Reset()
err = proxier.iptables.SaveInto(utiliptables.TableNAT, proxier.iptablesData)
if err != nil { // if we failed to get any rules
klog.ErrorS(err, "Failed to execute iptables-save, syncing all rules")
} else { // otherwise parse the output
existingNATChains = utiliptables.GetChainLines(utiliptables.TableNAT, proxier.iptablesData.Bytes())
}
上面的代码首先将数据以*bytes.Buffer对象保存起来。
这里的iptablesData保存了nat表的数据,而不是一个类似于existingFilterChainsData命名的对象
然后基于这些数据得到了当前存在的规则链的map。iptables规则的这些数据大致如下。
:KUBE-KUBELET-CANARY - [0:0]
:KUBE-MARK-DROP - [0:0]
:KUBE-MARK-MASQ - [0:0]
:KUBE-NODEPORTS - [0:0]
:KUBE-POSTROUTING - [0:0]
:KUBE-PROXY-CANARY - [0:0]
:KUBE-SEP-UEAYFIZ2IBK7HSGA - [0:0]
:KUBE-SERVICES - [0:0]
:KUBE-SVC-NPX46M4PTMTKRN6Y - [0:0]
基于这些数据得到的map类似下面
{"KUBE-SVC-NPX46M4PTMTKRN6Y": ":KUBE-SVC-NPX46M4PTMTKRN6Y - [0:0]"}
然后构造最终要导入到iptables里面的文本
iptables的规则就是一个文本,无论是导出还是导入
proxier.filterChains.Reset()
proxier.filterRules.Reset()
proxier.natChains.Reset()
proxier.natRules.Reset()
// 写入表头
utilproxy.WriteLine(proxier.filterChains, "*filter")
utilproxy.WriteLine(proxier.natChains, "*nat")
// 在构造的文本中写入规则链和规则
for _, chainName := range []utiliptables.Chain{kubeServicesChain, kubeExternalServicesChain, kubeForwardChain, kubeNodePortsChain} {
if chain, ok := existingFilterChains[chainName]; ok {
utilproxy.WriteBytesLine(proxier.filterChains, chain)
} else {
utilproxy.WriteLine(proxier.filterChains, utiliptables.MakeChainLine(chainName))
}
}
for _, chainName := range []utiliptables.Chain{kubeServicesChain, kubeNodePortsChain, kubePostroutingChain, KubeMarkMasqChain} {
if chain, ok := existingNATChains[chainName]; ok {
utilproxy.WriteBytesLine(proxier.natChains, chain)
} else {
utilproxy.WriteLine(proxier.natChains, utiliptables.MakeChainLine(chainName))
}
}
// 插入SNAT规则
utilproxy.WriteLine(proxier.natRules, []string{
"-A", string(kubePostroutingChain),
"-m", "mark", "!", "--mark", fmt.Sprintf("%s/%s", proxier.masqueradeMark, proxier.masqueradeMark),
"-j", "RETURN",
}...)
// Clear the mark to avoid re-masquerading if the packet re-traverses the network stack.
utilproxy.WriteLine(proxier.natRules, []string{
"-A", string(kubePostroutingChain),
// XOR proxier.masqueradeMark to unset it
"-j", "MARK", "--xor-mark", proxier.masqueradeMark,
}...)
masqRule := []string{
"-A", string(kubePostroutingChain),
"-m", "comment", "--comment", `"kubernetes service traffic requiring SNAT"`,
"-j", "MASQUERADE",
}
if proxier.iptables.HasRandomFully() {
masqRule = append(masqRule, "--random-fully")
}
utilproxy.WriteLine(proxier.natRules, masqRule...)
// 打标记
utilproxy.WriteLine(proxier.natRules, []string{
"-A", string(KubeMarkMasqChain),
"-j", "MARK", "--or-mark", proxier.masqueradeMark,
}...)
SNAT规则如下
-A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN
-A KUBE-POSTROUTING -j MARK --set-xmark 0x4000/0x0
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUER
初始化要插入的对象,在构造文本之前先将这些规则规整成一个个预定义的数据结构。
// 还在使用的nat规则链,用来过滤过时的规则链
activeNATChains := map[utiliptables.Chain]bool{} // use a map as a set
// 必要的数据结构
replacementPortsMap := map[utilnet.LocalPort]utilnet.Closeable{}
readyEndpointChains := make([]utiliptables.Chain, 0)
localEndpointChains := make([]utiliptables.Chain, 0)
// iptables规则参数,比如-m tcp之类,初始化长度为64,一是为了避免内存在分配
// 二是对于大多数情况足够了, 即使超过64也没关系,因为切片可以动态扩容
args := make([]string, 64)
// 计算所有服务的endpoint规则链的总数
proxier.endpointChainsNumber = 0
for svcName := range proxier.serviceMap {
proxier.endpointChainsNumber += len(proxier.endpointsMap[svcName])
}
// 获取本地地址
localAddrSet := utilproxy.GetLocalAddrSet()
nodeAddresses, err := utilproxy.GetNodeAddresses(proxier.nodePortAddresses, proxier.networkInterfacer)
至此,所需要的数据结构全部准备完毕。
根据最新的数据创建规则和规则链
这些逻辑在一个大循环中,仅仅是这个循环就占了500多行,所以这一部分也需要分解开来,首先只看循环本身。
for svcName, svc := range proxier.serviceMap {
}
这个循环的逻辑就是遍历当前的ServiceMap, 依次创建相应的规则链和规则,更具体的生成逻辑就是根据service找到对应的endpoint, 然后基于这些创建对应的规则。
首先是根据service找到endpoint,然后创建service对应的规则链。
// 对象转换
svcInfo, ok := svc.(*serviceInfo)
protocol := strings.ToLower(string(svcInfo.Protocol()))
svcNameString := svcInfo.serviceNameString
// 根据serviceName到endpointsMap找打对应的endpoint
allEndpoints := proxier.endpointsMap[svcName]
// 这里的过滤是为了topology aware endpoint这个特性
allEndpoints = proxy.FilterEndpoints(allEndpoints, svcInfo, proxier.nodeLabels)
// Scan the endpoints list to see what we have. "hasEndpoints" will be true
// if there are any usable endpoints for this service anywhere in the cluster.
var hasEndpoints, hasLocalReadyEndpoints, hasLocalServingTerminatingEndpoints bool
for _, ep := range allEndpoints {
// 判断hasEndpoints, hasLocalReadyEndpoints,hasLocalServingTerminatingEndpoints
}
useTerminatingEndpoints := !hasLocalReadyEndpoints && hasLocalServingTerminatingEndpoints
// Generate the per-endpoint chains.
readyEndpointChains = readyEndpointChains[:0]
localEndpointChains = localEndpointChains[:0]
for _, ep := range allEndpoints {
epInfo, ok := ep.(*endpointsInfo)
if !ok {
klog.ErrorS(err, "Failed to cast endpointsInfo", "endpointsInfo", ep)
continue
}
endpointChain := epInfo.endpointChain(svcNameString, protocol)
endpointInUse := false
// 检查是否已经存在endpoint链,否则就创建
// endpoint链就是 KUBE-SEP-XXXX
if chain, ok := existingNATChains[endpointChain]; ok {
utilproxy.WriteBytesLine(proxier.natChains, chain)
} else {
utilproxy.WriteLine(proxier.natChains, utiliptables.MakeChainLine(endpointChain))
}
// 表示是一个有效的链
activeNATChains[endpointChain] = true
args = append(args[:0], "-A", string(endpointChain))
args = proxier.appendServiceCommentLocked(args, svcNameString)
// 写入DNAT规则
utilproxy.WriteLine(proxier.natRules, append(args,
"-s", utilproxy.ToCIDR(net.ParseIP(epInfo.IP())),
"-j", string(KubeMarkMasqChain))...)
// Update client-affinity lists.
if svcInfo.SessionAffinityType() == v1.ServiceAffinityClientIP {
args = append(args, "-m", "recent", "--name", string(endpointChain), "--set")
}
// DNAT to final destination.
args = append(args, "-m", protocol, "-p", protocol, "-j", "DNAT", "--to-destination", epInfo.Endpoint)
utilproxy.WriteLine(proxier.natRules, args...)
}
// 确保KUBE-SVC-XXX链存在, 不存在就创建
svcChain := svcInfo.servicePortChainName
if hasEndpoints {
// Create the per-service chain, retaining counters if possible.
if chain, ok := existingNATChains[svcChain]; ok {
utilproxy.WriteBytesLine(proxier.natChains, chain)
} else {
utilproxy.WriteLine(proxier.natChains, utiliptables.MakeChainLine(svcChain))
}
activeNATChains[svcChain] = true
}
// Capture the clusterIP.
if hasEndpoints {
args = append(args[:0],
"-m", "comment", "--comment", fmt.Sprintf(`"%s cluster IP"`, svcNameString),
"-m", protocol, "-p", protocol,
"-d", utilproxy.ToCIDR(svcInfo.ClusterIP()),
"--dport", strconv.Itoa(svcInfo.Port()),
)
// 写入KUBE-SVC-XXX链的规则
utilproxy.WriteRuleLine(proxier.natRules, string(kubeServicesChain), append(args, "-j", string(svcChain))...)
}
关于externalService, loadbalancer类型的代码这里就跳过了。
上面的代码总结起来就是创建KUBE-SVC-XXX, KUBE-SEP-XXX等规则链,然后在这些链上写入规则,比如
-A KUBE-SERVICES -d 10.152.183.1/32 -p tcp -m comment --comment "default/myservice cluster IP" -m tcp --dport 80 -j KUBE-SVC-NPX46M4PTMTKRN6Y
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/myservice" -m statistic --mode random --probability 0.500000000 -j KUBE-SEP-72LVGSP46NP3XHTG
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/myservice" -j KUBE-SEP-EDGGJ3GHDFLJOF2D
-A KUBE-SEP-72LVGSP46NP3XHTG -s 10.0.20.4/32 -m comment --comment "default/myservice" -j KUBE-MARK-MASQ
-A KUBE-SEP-72LVGSP46NP3XHTG -p tcp -m comment --comment "default/myservice" -m tcp -j DNAT --to-destination 10.0.20.4:80
删除不在使用的规则和规则链
基于existingNATChains, activeNATChain确定不在需要的链和规则
for chain := range existingNATChains {
if !activeNATChains[chain] {
chainString := string(chain)
// 如果不是k8s创建的链就跳
if !strings.HasPrefix(chainString, "KUBE-SVC-") && !strings.HasPrefix(chainString, "KUBE-SEP-") && !strings.HasPrefix(chainString, "KUBE-FW-") && !strings.HasPrefix(chainString, "KUBE-XLB-") {
// Ignore chains that aren't ours.
continue
}
// 删除链之前确保链存在
// -X KUBE-SVC-XXXX, KUBE-SEP-XXXX
utilproxy.WriteBytesLine(proxier.natChains, existingNATChains[chain])
utilproxy.WriteLine(proxier.natRules, "-X", chainString)
}
}
关于filter表的规则和规则链这里就略去了,主要是一些过滤的规则,比如过滤掉非法状态的数据包,接受哪些状态的数据包之类的。
最后就是将数据全部写入要生成的文本中
utilproxy.WriteLine(proxier.filterRules, "COMMIT")
utilproxy.WriteLine(proxier.natRules, "COMMIT")
// Sync rules.
// NOTE: NoFlushTables is used so we don't flush non-kubernetes chains in the table
proxier.iptablesData.Reset()
proxier.iptablesData.Write(proxier.filterChains.Bytes())
proxier.iptablesData.Write(proxier.filterRules.Bytes())
proxier.iptablesData.Write(proxier.natChains.Bytes())
proxier.iptablesData.Write(proxier.natRules.Bytes()).Bytes())
刷新iptables规则
至此用来导入到iptables的规则文本已经创建完毕,可以导入这些文本到iptables里面了。
err = proxier.iptables.RestoreAll(proxier.iptablesData.Bytes(), utiliptables.NoFlushTables, utiliptables.RestoreCounters)
if err != nil {
klog.ErrorS(err, "Failed to execute iptables-restore")
return
}
success = true
restore就是调用iptables-restore命令,具体命令差不多如下。
iptables-restore --noflush --counters < xxxx
–noflush保证不会刷掉之前已有的规则,–counters保证统计详细不会重置。
删除过时的conntrack连接
这部分直接看代码就行。
klog.V(4).InfoS("Deleting conntrack stale entries for Services", "ips", conntrackCleanupServiceIPs.UnsortedList())
for _, svcIP := range conntrackCleanupServiceIPs.UnsortedList() {
if err := conntrack.ClearEntriesForIP(proxier.exec, svcIP, v1.ProtocolUDP); err != nil {
klog.ErrorS(err, "Failed to delete stale service connections", "ip", svcIP)
}
}
klog.V(4).InfoS("Deleting conntrack stale entries for Services", "nodeports", conntrackCleanupServiceNodePorts.UnsortedList())
for _, nodePort := range conntrackCleanupServiceNodePorts.UnsortedList() {
err := conntrack.ClearEntriesForPort(proxier.exec, nodePort, isIPv6, v1.ProtocolUDP)
if err != nil {
klog.ErrorS(err, "Failed to clear udp conntrack", "port", nodePort)
}
}
iptables数据流
既然讲解iptables模式的kube-proxy, 自然无法避免iptables的相关知识,下面是一张比较详细的iptables数据流的图示。
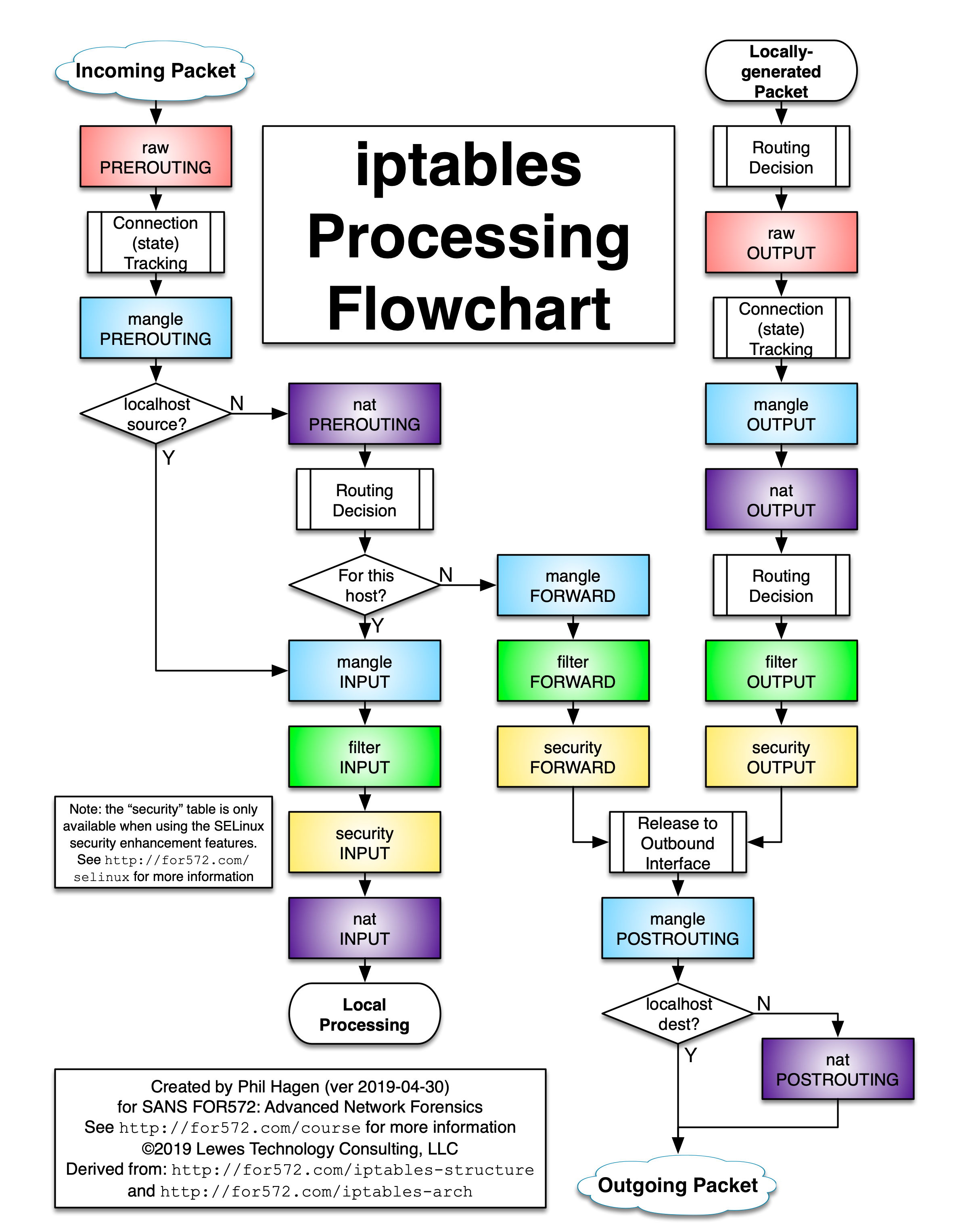
如果搞不清各个链和表之间的关系,可以参考上面的图。
kube-proxy一般只用到了两张表, nat,filter。
本文只讲解两条数据流
-
通过service到目标pod的数据流,即 pod1 -> service -> DNAT -> pod2
-
通过service到节点端口(nodePort)的数据流, 即 pod1 -> service -> DNAT -> nodeport -> pod2
通过service到目标pod的数据流
这里以下面的service为例, 然后梳理与它相关的iptables规则
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: myservice
type: ClusterIP
创建完成之后可以看到它对应的endpoint和cluster ip
Name: myservice
Namespace: default
Labels: app=myservice
Annotations: <none>
Selector: <none>
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.152.183.1
IPs: 10.152.183.1
Port: http 80/TCP
TargetPort: 80/TCP
Endpoints: 10.0.20.4:80, 10.0.22.3:80
Session Affinity: None
Events: <none>
当service创建完成之后,就可以看看iptables的规则了,规则可以在k8s集群中的任意节点可以查看, 为了简单起见,文中会去掉与这个service无关的规则。
规则可以通过iptables-save完整输出,这个命令会输出所有表的所有链。
如果要查看指定表的规则,可以通过iptables -vnL -t {表名}查看, 比如nat, 如果不指定-t参数, 默认是filter表。
假设集群中的一个pod(10.0.21.12)访问此service, 那么经过的iptables规则如下。
# nat表
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A KUBE-SERVICES -d 10.152.183.1/32 -p tcp -m comment --comment "default/myservice cluster IP" -m tcp --dport 80 -j KUBE-SVC-NPX46M4PTMTKRN6Y
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/myservice" -m statistic --mode random --probability 0.500000000 -j KUBE-SEP-72LVGSP46NP3XHTG
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/myservice" -j KUBE-SEP-EDGGJ3GHDFLJOF2D
# 注意只有源ip是10.0.20.4/32
# 这是为了解决自己访问自己的service, 如果不做特殊处理,那么会发生错误
-A KUBE-SEP-72LVGSP46NP3XHTG -s 10.0.20.4/32 -m comment --comment "default/myservice" -j KUBE-MARK-MASQ
-A KUBE-SEP-72LVGSP46NP3XHTG -p tcp -m comment --comment "default/myservice" -m tcp -j DNAT --to-destination 10.0.20.4:80
# KUBE-MARK-MASQ就是简单的打个标记
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
所以数据流如下
-
所以首先通过dns得到service的cluster ip
-
宿主机在收到pod的数据包之后会先进入PREROUTING继而进入KUBE-SERVICES链,最红匹配到KUBE-SVC-NPX46M4PTMTKRN6Y链
-
KUBE-SVC-NPX46M4PTMTKRN6Y会以50%的概率随机选择KUBE-SEP-EDGGJ3GHDFLJOF2D和KUBE-SEP-72LVGSP46NP3XHTG
-
这里假设选择了KUBE-SEP-72LVGSP46NP3XHTG
-
KUBE-SEP-72LVGSP46NP3XHTG链会将流量通过DNAT转发到10.0.20.4:80
这里有一个问题,那就是service的后端访问自己对应的service是否会建立不了连接?因为DNAT并不会修改源IP,那么自己访问自己,发出的时候走了iptables,然后回包的时候发现包是自己,那么肯定不会过iptables了,也不会过网桥,那么这里会发生错误,怎么解决呢?kube-proxy的解决办法是打一个标记,在POSTROUTING的时候做SNAT
假设service的后端访问此service, 即10.0.20.4 -> myservice(10.152.183.1)
那么在nat表与上面的数据流没有多大区别,但是在filter表上会有一些区别, 因为在nat表里面会进入KUBE-MARK-MASQ链打上一个0x4000的标记。
然后就会依次匹配到POSTROUTING链上的SNAT规则。
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
-A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN
-A KUBE-POSTROUTING -j MARK --set-xmark 0x4000/0x0
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE
所以service后端访问自己对应的service看到的源IP是service的cluster IP。
通过service到节点端口(nodePort)的流量
假设一个外部的主机访问一个类型是nodePort的service。
那么匹配到的iptables规则如下。
# nat表
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst
-type LOCAL -j KUBE-NODEPORTS
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/myservice" -m tcp --dport 80 -j KUBE-SVC-NPX46M4PTMTKRN6Y
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/myservice" -m statistic --mode random --probability 0.500000000 -j KUBE-SEP-72LVGSP46NP3XHTG
-A KUBE-SVC-NPX46M4PTMTKRN6Y -m comment --comment "default/myservice" -j KUBE-SEP-EDGGJ3GHDFLJOF2D
# 注意只有源ip是10.0.20.4/32
-A KUBE-SEP-72LVGSP46NP3XHTG -s 10.0.20.4/32 -m comment --comment "default/myservice" -j KUBE-MARK-MASQ
-A KUBE-SEP-72LVGSP46NP3XHTG -p tcp -m comment --comment "default/myservice" -m tcp -j DNAT --to-destination 10.0.20.4:80
可以发现数据流与到service的数据流基本一致,不同点在于流量入口的匹配的是节点的端口
所以数据流如下
-
节点接受到数据包,KUBE-NODEPORTS链匹配到流量继而转发给KUBE-SVC-NPX46M4PTMTKRN6Y链
-
KUBE-SVC-NPX46M4PTMTKRN6Y会以50%的概率随机选择KUBE-SEP-EDGGJ3GHDFLJOF2D和KUBE-SEP-72LVGSP46NP3XHTG
-
这里假设选择了KUBE-SEP-72LVGSP46NP3XHTG
-
KUBE-SEP-72LVGSP46NP3XHTG链会将流量通过DNAT转发到10.0.20.4:80
开篇的答案
-
为什么理论上ipvs的转发性能高于iptables却默认是iptables而不是ipvs?
我也没有确切的答案,我搜索到的说法,大都是是说长连接iptables会更好,但是ipvs的tcp连接超时时间是可调的,我没有找到一个足够信服的答案。
-
kube-proxy怎么保持规则的同步和生成对应的规则,第一次全量数据是怎么拿到的?
kube-proxy通过informer监听service,endpoint对象, informer能够提供可靠的同步机制,同步完成之后就拿到了全量数据。
-
iptables怎么保留iptables上已有的规则,怎么确保自己的规则没有被刷掉?
iptables-restore有一个–noflush参数,这个参数会让iptables不覆盖已有的规则
总结
可以看到kube-proxy的代码有三个比较重要的对象。
-
Options
-
ProxyServer
-
Proxier
Options负责承载所有的配置项然后传给ProxyServer,ProxyServer作为一个大管家配置一些通用的内核参数并根据参数选择合适的proxier来转发流量,而proxier会实现OnServiceAdd, OnXxxYyy等接口来作为informer的回调函数以监听集群中资源的变化,基于这些变化更新规则,同步规则。但是每个informer都是作为一个单独的gorouting来运行的,存在资源竞争,为了让代码高内聚,第耦合,proxier不太应该管这件事,所以需要借助外部的syncRunner对象来负责这个脏活,这个runner会控制并发,控制定时任务,控制重试任务等。