使用n8n创作短篇小说
需要提前说明的是,本人不会使用本工作流用来写小说并投稿只是用于研究目的,因为写小说这个工作流感觉不简单也不算太复杂,适合用来深入n8n的使用。
n8n是什么?
会点进这篇文章的人应该都知道n8n是一个开源的工作流自动化平台吧?总的来说,它是一个可以通过配置工作流来实现自动化任务的平台,比如自动化发送邮件、自动化回复邮件等各种可以使用电脑完成的事情, 这些其实通过写程序脚本也能完成, 但是自己写脚本稍微比较烦人的一点是需要去研究各种接口和服务, 而n8n比较突出的一点是集成了各种节点(插件), 这样使用起来就比较方便,不用自己去看各种接口怎么配置,可以从已有的节点中挑选顺手的工具, 而且还有庞大的社区插件可以使用, 这也是我选择n8n而不是dify的原因。
安装n8n
安装有两种办法,这个参考官方文档就行,这里简单概括一下
使用npm安装
npm install -g n8n
n8n
使用docker安装
一定要创建一个volume呀, 不然n8n的数据就没办法持久化了
docker volume create n8n_data
docker run -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8n
创建工作流
在创建工作流之前,我们首先需要规划一下整个工作流的逻辑。 众所周知的大多数模型都是有输出限制的,比如DeepSeek一般是4096个Token, 差不多3000个汉字左右(似乎实际使用中, 只有2000个汉字左右), 所以我们需要把小说内容生成分成若干个章节, 然后根据大纲和每章的章节安排来生成每章的小说内容,最后将这些内容组合在一起就可以了。
当然啦,还有号称可以输出超级长文本和有超级上下文的AI模型,这里就不考虑了, 因为我也没有测试过,而且本文的目的也主要是研究怎么使用n8n,而不是真的为了来产生垃圾小说和污染互联网。
我的规划如下
- 根据用户输入,使用DeepSeek生成标题,大纲,章节安排等
- 将生成的章节安排通过
Loop over items节点来循环生成每章的小说内容 - 将生成的小说内容组合在一起, 并发送到用户的邮箱中
n8n支持很多的AI模型, 比如DeepSeek, GPT, Gemini(有免费调用额度, 国内使用需要绕一下)等, 这里我使用的是DeepSeek, 因为DeepSeek的输出比较符合我的预期
配置完成后的效果图如下
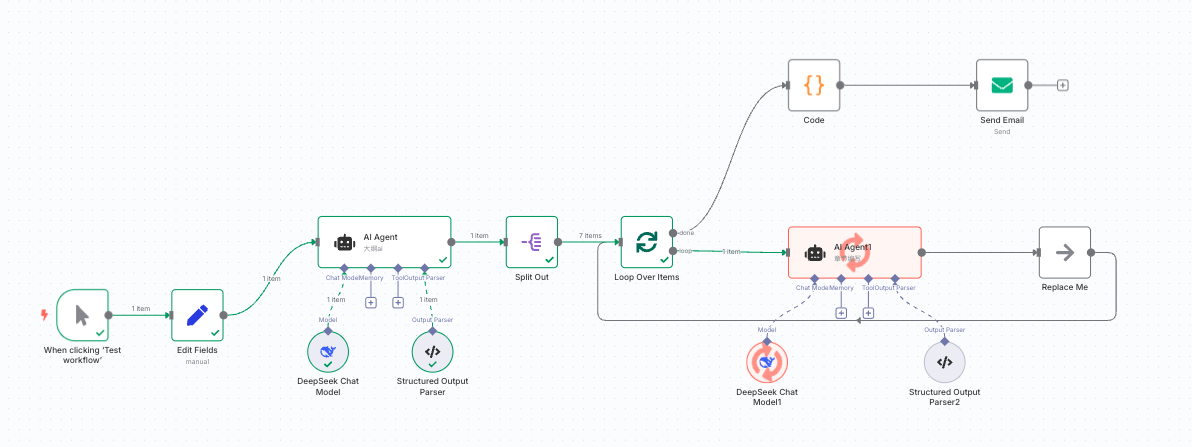
整个工作流可以分为上下两个部分
- 生成内容
- 发送内容
生成内容的部分, 依次使用了以下节点
- 手动出发节点
- Set节点,用来设置小说主题
- AI Agent节点,用来生成标题,大纲,章节安排等
- Split Out节点,选择对应的章节列表字段,转换成一个列表给后面的
Loop over items节点使用 - Loop over items节点,用来循环生成每章的小说安排
- AI Agent节点,用来生成每章的小说内容
发送内容的部分, 依次使用了以下节点
- Code节点,用来将生成的小说内容组合在一起
- Email节点,用来发送邮件
其实可以使用chat trigger
配置AI Agent
第一个Agent的主要注意点是我们需要让ai输出对应的输出格式,这样我们后续才方便遍历章节安排。
点击下图的"required specific output format"按钮,激活之后,agent节点下面就会过一个"+“号
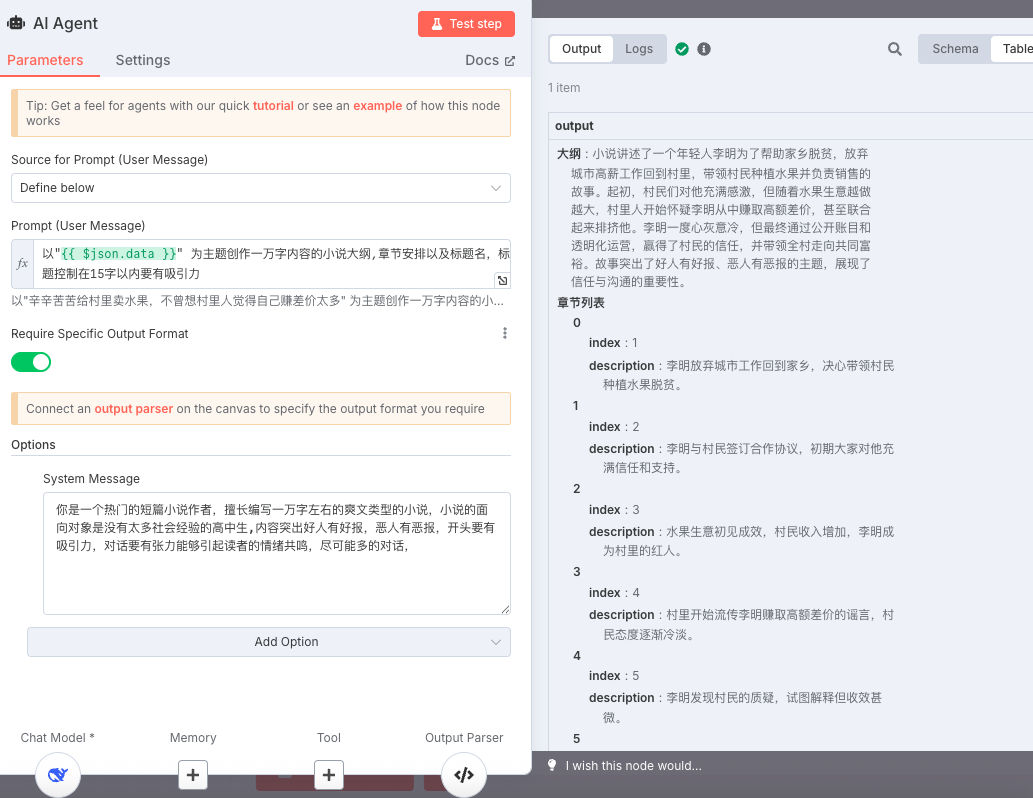
点击”+“号,就可以配置输出格式了, 这里我配置的输出格式如下
{
"大纲": "California",
"章节列表": [{
"index": 0,
"description": ""
}],
"标题":""
}
效果如下
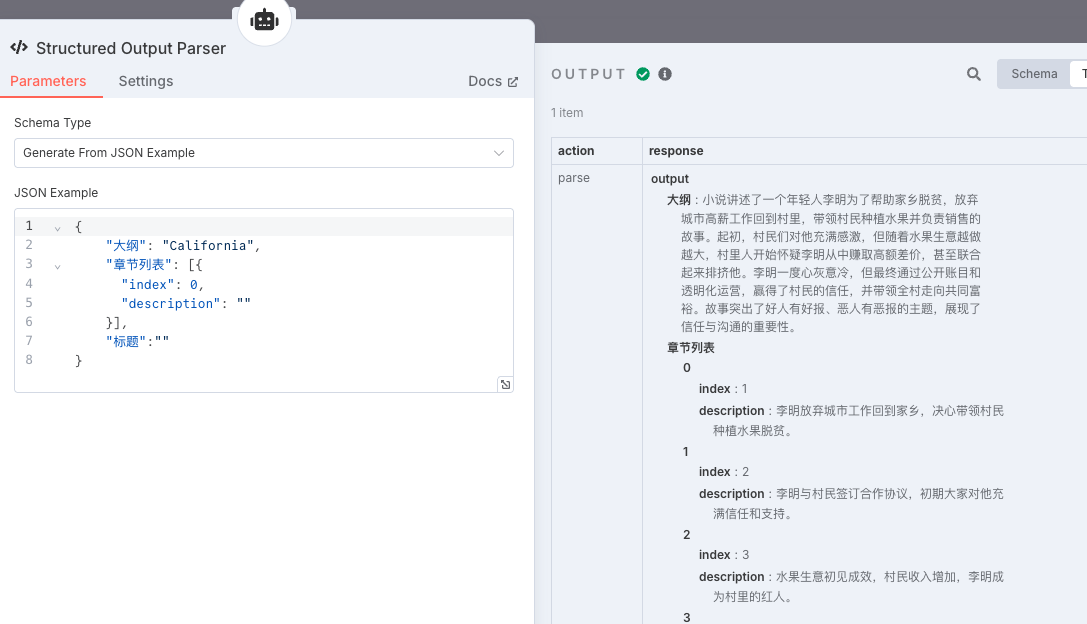
使用中文作为字段名也挺好的。
第二个Ai Agent就不需要指定输出格式了,因为输出就一个文本
DeepSeek的模型配置并不复杂,要配置的选项就一个api key,所以找到deepseek官网充值点钱然后创建一个api key就行。
配置邮箱
不同的邮箱使用可能会有一些差异,我这里使用的是qq邮箱。 要注意的是,在邮箱凭证中填写的邮箱密码不是qq密码,而是qq邮箱生成的一个授权码,我们需要开通对应邮箱的"POP3/IMAP/SMTP/Exchange/CardDAV 服务”, 开通这个服务还需要手机验证,具体的操作方法可以问问百度或者AI,这里就不赘述了。
使用代码聚合内容
我比较习惯使用Python, 所以使用以下代码来聚合最终的内容
# Loop over input items and add a new field called 'myNewField' to the JSON of each one
data = ""
length = len(_input.all())
for index, item in enumerate(_input.all()):
if index == length - 1:
data += item.json.output
else:
data += (item.json.output + "\n" + "------")
return {"data": data}
测试小技巧
测试工作流很简单,点一下"test workflow"就行,但是调用AI Agent可能需要钱或者很慢,所以我们可以在点击"Test App"之后将结果Pin一下,这样后面的节点就可以使用前面Pin住的节点的数据,会快很多。
邮件效果

公网访问
公网访问有很多种方式的啦,比如搞一台有公网ip的服务器,或者使用ngrok或者frp之类的工具内网穿透一下, 这里就不赘述了, 有兴趣的可以自己去了解一下。
这里主要介绍cloudflare的tunnel的使用, 前提是你要有一个域名哈,域名你可以买一个最便宜的或者申请一个免费的域名,我就是用的免费的域名,自己用的话完全够用。
设置tunnel
假设你已经有了cloudflare的账户及域名。 那么你可以到"Zero Trust" -> “网络” -> “Tunnels"创建一个tunnel(隧道) 点击创建隧道之后,根据提示一步步操作就行,我使用的是Cloudflared命令连接隧道。
最后就是配置公网域名映射,我的配置如下
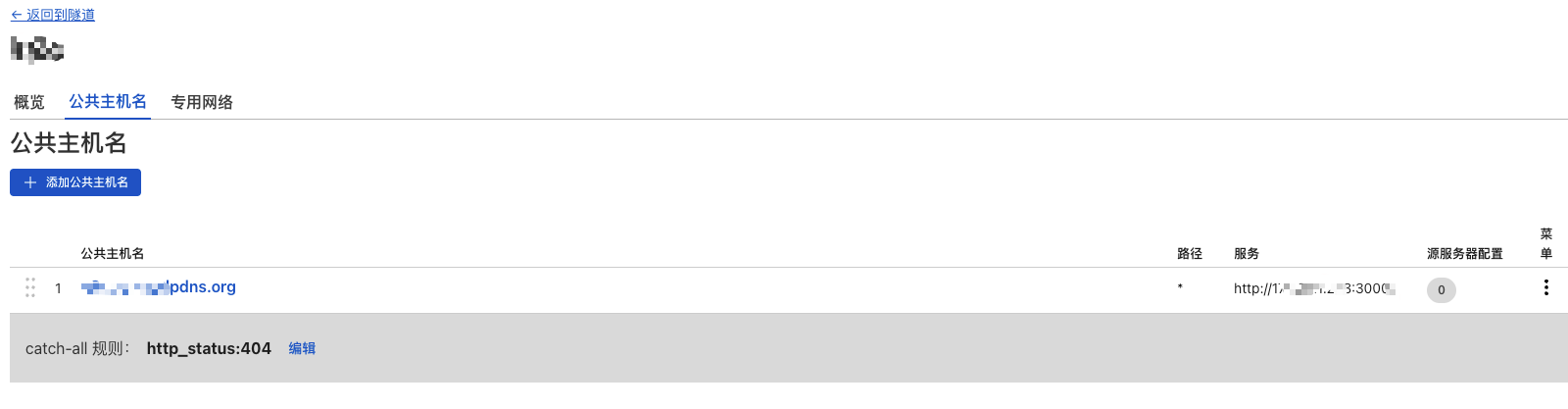
通过这个域名就能访问你内网的服务啦,而且还是https协议的。
使用免费的Gemini接口
如果你有一个代理,并且通过这个代理能拿到Gemini的API Key的话,那么你可以在上一部公网访问的基础上,使用nginx或者caddy之类的web服务器在本地来代理Gemini的API,再通过cloudflare的tunnel转接一下,这样就可以使用免费的Gemini接口了。
我使用的caddy,配置如下
https://你的域名 {
log {
output file /var/log/caddy.gemini.log {
roll_size 100mb
roll_keep 5
roll_keep_for 720h
}
}
reverse_proxy https://generativelanguage.googleapis.com {
header_up Host generativelanguage.googleapis.com
header_up X-Forwarded-Proto {scheme}
header_up X-Forwarded-For {remote}
}
}
工作流文件
本文的n8n的工作流文件内容放在 https://github.com/youerning/blog/blob/master/n8n/novel-workflow.json 了,有兴趣可以自己下载下来看看
总结
个人认为,使用诸如n8n这样的工作流平台要要比自己维护脚本要方便一些,特别是n8n集成了超级多的插件或者说节点之后就用起来很爽,跟代码比起来肯定不够灵活,但是作为工作流平台我觉得已经超级方便了,而且使用大模型也非常的方便